|
|
MINISTÉRIO DA EDUCAÇÃO UNIVERSIDADE
FEDERAL DO PARANÁ
SETOR DE TECNOLOGIA DEPARTAMENTO DE ENGENHARIA ELÉTRICA |

Disciplina: Processamento Digital de
Sinais
Professor:
Eduardo Parente Ribeiro
Processador Digital de
Sinais - DSP
Alunos:
Antonio
Carlos Gonçalves
Graziela Wehmuth Schmitt
Ivo Ribeiro dos Santos Jr.
Rodrigo Harmuch Perez
Curitiba, Novembro de 1999
Sumário
1.
Introdução.............................................................................................................................................................. 2
2. Desenvolvimento................................................................................................................................................. 2
2.1 O que é DSP e para que
serve...................................................................................................................... 2
2.2. Histórico.............................................................................................................................................................. 4
2.3. Hardware........................................................................................................................................................... 5
2.3.1. Fixed-Point x Floating-Point DSPs.......................................................................................................... 5
2.3.2. Fixed-Function x Variable-Function DSPs............................................................................................ 6
2.3.3. Componentes Básicos de um DSP............................................................................................................. 7
2.3.3.1. Program Control Unit (PCU)..................................................................................................................... 7
2.3.3.2. Arithmetic Logic Unit (ALU)...................................................................................................................... 7
2.3.3.3. Address Generetion Unit (AGU)................................................................................................................ 7
2.3.3.4. Floating-Point Unit (FPU).......................................................................................................................... 7
2.3.3.5. Registradores............................................................................................................................................... 7
2.3.3.6. Memória RAM........................................................................................................................................... 7
2.3.3.7. ROM e EPROM......................................................................................................................................... 8
2.3.3.8. Shifters e Rotators....................................................................................................................................... 8
2.3.3.9. Contadores.................................................................................................................................................. 8
2.3.3.10. DAC e ADC.............................................................................................................................................. 8
2.3.4. Fractional Addressing (endereçamento fracionado)............................................................................ 8
2.3.5. A questão do Branching.............................................................................................................................. 8
2.3.6. Paralelismo e pipeline em um DSP de um único chip........................................................................... 9
2.3.7. O problema da atualização de parâmetros............................................................................................. 9
2.3.8. Microprogramando um DSP...................................................................................................................... 9
2.3.9. Array processors......................................................................................................................................... 10
2.3.10. Arquiteturas multiprocessadas.............................................................................................................. 10
2.4. Software........................................................................................................................................................... 11
2.4.1. A Família TMS320C 5x e 8x................................................................................................................... 11
2.4.1.1. Série
TMS320C5x Fixed Point DSP......................................................................................................... 11
2.4.1.1.1. Principais
Características................................................................................................................... 11
2.4.1.1..2. Datasheets......................................................................................................................................... 12
2.4.1.1..3. Aplicações......................................................................................................................................... 12
2.4.1.1.4. Manuais do
usuário............................................................................................................................ 14
2.4.1.2. Normandy (Tecnologia da National compatível
com TMS320C5X)...................................................... 14
2.4.1.3. Série
TMS320C8x Multiprocessor DSP................................................................................................... 16
2.4.2. Processador Master (MP)......................................................................................................................... 16
2.4.2.1. A unidade de
ponto flutuante.................................................................................................................... 17
2.4.2.2.
Características da FPU do Processador Master........................................................................................ 18
2.4.3. DSPs de Processamento Paralelo Avançado (PP)............................................................................... 19
2.4.4. Controlador de Transferências (TC - Transfer Controller)............................................................... 20
2.4.5. DSP Benchmarking.................................................................................................................................... 21
2.5. Exemplos de Aplicações
com DSPs..................................................................................................... 24
2.5.1. Parte Prática utilizando o Starter Kit (DSK) do DSP TMS320C50................................................. 24
2.5.2. Controlador de Vídeo (VC)
com TMS320C80.................................................................................... 25
2.6. Diferenças entre um processador
de uso genérico e um DSP........................................... 26
2.7. Desenvolvimento de
sistemas DSP..................................................................................................... 28
2.8. Mercado............................................................................................................................................................. 29
3. Conclusão............................................................................................................................................................. 29
Referências
Bibliográficas........................................................................................................................... 29
1. Introdução
DSPs são microprocessadores desenhados para realizar processamento digital de sinais. Essa tecnologia tem se desenvolvido imensamente em conjunto com aplicações emergentes como comunicação sem fio, vídeo e áudio. Atualmente existem no mercado uma enorme gama de DSPs, desenhados para diferentes aplicações.
Neste trabalho será visto o que são e para que servem os DSPs e feito um breve histórico a respeito dos mesmos.
Serão mostrados quais os tipos existentes de DSPs, seus componentes básicos, processadores e arquiteturas.
Na seqüência, falaremos da família TMS320C 5x e 8x, suas principais características e exemplos de aplicações com DSPs TMS320C50 e TMS320C80.
Em seguida serão abordadas as diferenças de um processador de uso genérico e um DSP.
Para finalizar, mostraremos como se desenvolvem os sistemas DSPs, quais os custos e o mercado para os mesmos.
2. Desenvolvimento
2.1 O que é DSP e para que serve
O ambiente natural que nós buscamos interpretar é analógico. Sinais variam de forma contínua com o tempo e podem tomar qualquer valor existente. O domínio digital é fixo em dois valores: alto e baixo. A conversão dos sinais do domínio analógico para o digital (e vice versa) é essencial para capturar, manipular e reintroduzí-los ao meio ambiente. As vantagens ganhas com a manipulação digital justificam tal conversão. Dispositivos que fazem essa conversão são chamados de conversores analógico-digitais e conversores digital-analógicos. A representação dos sinais analógicos no meio digital é feita por amostragem.
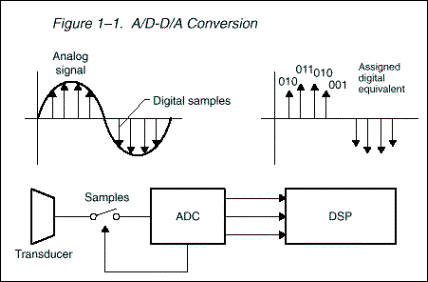
Figura 1 – Conversão A/D – D/A
Telecomunicações, multimídia e produtos eletrônicos de consumo usam processamento digital de sinais (DSP) para comprimir, comunicar e modificar sinais. Em sua maioria, esses sinais são áudio, vídeo ou sinais de dados. Esses sinais contêm uma quantidade de informação demasiadamente grande para se ter uma comunicação prática ou dispositivos de armazenamento de baixo custo tais como uma secretária eletrônica digital. Além disso, provedores de serviços de comunicação querem oferecer o máximo de linhas que um link digital pode suportar. Como resultado, compressão é utilizada para reduzir enormemente a quantidade de informação necessária para se comunicar e armazenar áudio, vídeo e dados. DSP também é usado para aumentar a qualidade de áudio e vídeo através de redução de ruídos, eco, entre outros.
Um sistema de DSP é a parte do produto que realiza o processamento digital do sinal, faz a conversão do sinal de analógico para digital e vice versa e faz compressão, comunicação ou modificação (melhoramento) desses sinais. Os componentes de um sistema DSP são a placa de DSP e o software de DSP.
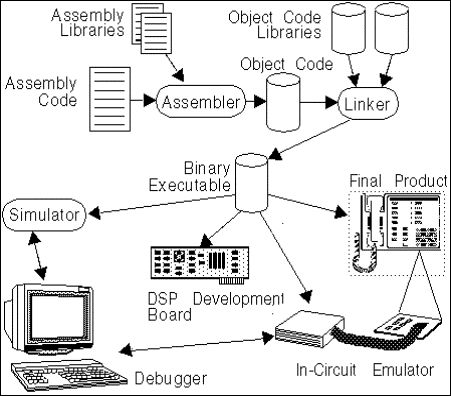
Figura 2 – Processo de desenvolvimento de um DSP
A Figura 2 ilustra um exemplo do processo de desenvolvimento de um sistema DSP. Ferramentas de desenvolvimento de software permitem que o desenvolvedor programe o código do dispositivo, depure, otimize e simule o código antes de imprimir na ROM o programa final.
Existem ainda no mercado bibliotecas de domínio público com as principais funções utilizadas em aplicações padrões de processamento digital de sinal.
O Hardware DSP consiste de circuitos de I/O e controle, além do processador digital de sinal (chip). Os processadores DSPs são microprocessadores com capacidade matemática aprimorada para processamento de sinal. Muitos DSPs são mais simples que um microprocessador PC o que faz deles mais baratos e, consequentemente, viáveis para o mercado. Essa capacidade matemática melhorada faz com que os DSPs sejam capazes de realizar tarefas extremamente complexas para processamento de sinal.
2.2. Histórico
No início dos anos 80 foi introduzido comercialmente o primeiro DSP. Hoje acredita-se que esse mercado atinja US$3 milhões em 1998 com um crescimento anual de 35%.
Na área de processamento digital de som, por exemplo, desde o primeiro som sintetizado em 1957 que se buscava uma forma de se criar sons naturais eletronicamente. Somente depois de décadas de pesquisa que, em 1979, graças à queda de preço das memórias semicondutoras, que se tornou possível a criação do primeiro sintetizador de som comercial baseado em amostragem de 8 bits. Em 1981, o custo de um sintetizador foi trazido a uma faixa de preço abaixo de US$10,000.
Nessa mesma faixa de preços, em 1982, surgiu o DMX-1000, desenvolvido por Dean Wallraff de Boston. Ele foi o primeiro DSP realmente programável do mercado de processamento de som, capaz de processar sons de fontes externas assim como sintetizar seus próprios sons.
Os primeiros e fracassados FixedPoint DSPs:
|
1978 |
American Microsystems, Inc. (release delayed until 1983 or so) |
S2811 |
|
1979 |
Intel Corp. (onboard A/D, D/A, but no multiplier!) |
2920 |
|
1979 |
AT&T (internal R&D only) |
DSP1 |
|
1980 |
Ricoh / AMI (redesign of S2811) |
S28211 |
|
1980 |
NEC |
uPD7720 |
Não houve sucesso real até 1982; os processadores eram muito lentos, engenheiros não estavam habituados aos DSPs e as ferramentas de desenvolvimento eram muito pobres. A partir de 1982 surgiu a primeira geração de sistemas DSP de um único chip fixed-point programável conforme mostra a Figura 3.
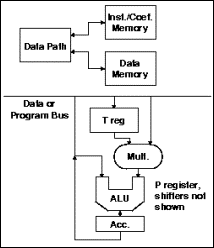
Figura 3 – Primeira geração DSP
· 16bit fixedpoint
· Harvard architecture
· 2 instructions/FIR tap
· 390 ns MAC time (228 ns today)
· Special addloadwriteback instruction
· Two address registers
· No guard bits
· No hardware looping
· One accumulator
O mercado de sistemas DSP de um único chip fixed-point DSP programável:
|
1994 |
$0.9 billion |
|
1995 |
$1.2 billion |
|
1996 |
$1.7 billion |
|
1997 |
$2.3 billion |
|
1998 |
$3.5 billion |
2.3. Hardware
2.3.1. Fixed-Point x Floating-Point DSPs
Existem dois tipos básicos de DSP; aqueles que realizam operações de ponto fixo (fixed-point operations) e aqueles que realizam operações de ponto flutuante (floating point operations). Fixed-Point DSPs possuem um custo mais baixo, porém oferecem um menor alcance de representação. Para compensar essa falta, desenvolvedores precisam fazer um grande esforço para tratar do reescalonamento dos números em suas aplicações. Essa engenharia numérica pode ser tão trabalhosa quanto o desenvolvimento da aplicação em si. Floatinf-Point DSPs oferecem uma grande extensão de representação tais porém eles são mais caros. A precisão dos Floating-Point DSPs faz com que o desenvolvimento de aplicações se torne mais fácil, porém elas têm um maior custo computacional e seu consumo de energia é maior. Fixed-Point DSPs, requerem menos energia e são menores fisicamente e usam chip de memória menores que os Floating-Point DSPs. Isso os torna mais viáveis para produtos alimentados por bateria ou produtos grandes que não poderiam abrigar uma placa DSP de grande volume.
|
|
Fixed-Point DSP |
Floating-Point DSP |
|
Custo |
Mais Barato |
Mais Caro |
|
Consumo de Energia |
Menor |
Maior |
|
Desenvolvimento de
Aplicações |
Extremamente difícil |
Fácil |
|
Representação (16 bits) |
[0..65535] |
[0..6,27x1057] |
Algumas razões para se escolher um Floating-Point DSP:
·
Pequeno
Volume de produção - Não quer mexer com as limitações do Ponto Fixo.
·
Pouco
tempo para o mercado.
·
Algoritmos
adaptativos ou filtros muito rígidos podem se tornar instáveis com Ponto fixo.
·
Precisa
do alto alcance de precisão do DSP de ponto flutuante.
·
Tipicamente,
os DSPs de ponto flutuante possuem mais espaço de endereçamento e um ISA mais
poderoso.
Algumas razões para se escolher um Fixed-Point DSP:
·
Baixo
Custo
·
Menor
poder (aplicabilidade)
·
Maior
taxa de execução de instruções (por segundo)
·
Grande
volume de produção faz com que o esforço extra de desenvolvimento valha a pena
·
Implementar
algoritmos de ponto fixo ou algoritmos que exige exatidão de bits tais como
compressão de voz e vídeo.
Praticamente tudo o que se pode fazer com um Foating-Point DSP pode ser feito com o Fixed-Point DSP. O que deve ser analisado é o custo benefício do desenvolvimento, ou seja, deve-se identificar se a economia feita com Fixed-Point DSPs paga o custo de desenvolvimento mais elevado que ele acarreta.
Para a maioria das aplicações devemos considerar os seguintes fatores para calcular o seu custo:
·
Custo
do processador
·
Custo
da memória, buffers, ADC, DAC ...
·
Custo
de fabricação da placa
·
Custo
do Gabinete
·
Custo
de embalagem
Alguns outros custos “escondidos” são:
·
Marketing
·
O
produto funciona bem?
·
Tempo
de mercado (timing)... se você atrasa
você perde!
·
Ferramentas...
é fácil trabalhar com ela...
·
Você
pode adicionar novos recursos ou melhorar seu código?
2.3.2.
Fixed-Function x Variable-Function DSPs
Um outro modo de se classificar arquiteturas DSP é dividi-la em DSP para aplicações específicas e DSP para aplicações genéricas.
Os DSPs para aplicações específicas são semelhantes aos sintetizadores e modificadores de sinal analógicos criados na década de 60. Eles implementam diversos filtros, osciladores, geradores de envelopes. Ou seja, um fixed-function DSP possui unidades funcionais específicas, que o tornam mais apropriado a uma determinada aplicação.
Os variable-function DSPs, por outro lado, possuem uma coleção mais flexível de unidades funcionais. Essas unidades consistem de múltiplas memórias e processadores primitivos. Cada um desses processadores primitivos executam computações específicas tais como cálculo de endereços, multiplicação/adição, table lookup, contadores de ticks clock, I/O handlers, etc...
2.3.3.
Componentes Básicos de um DSP
2.3.3.1. Program
Control Unit (PCU)
A PCU executa instruction fetch, instruction decoding, e faz o tratamento dos sinais de interrupção externos. Quando ela recebe uma interrupção, é determinada a prioridade da interrupção e, se necessário, passa o controle para a rotina de tratamento da interrupção (traps). Quando o tratamento da interrupção for completado, a PCU retorna à execução do programa.
2.3.3.2. Arithmetic
Logic Unit (ALU)
A ALU executa operações lógicas e aritméticas (tais como add, sub, complemento), tipicamente em palavras de inteiros. A PCU diz à ALU que operação executar. O controle da saída da ALU indica erros e outras condições à medida que eles ocorrem.
2.3.3.3. Address
Generetion Unit (AGU)
A AGU é um tipo de ALU para cálculo de endereços. Instruções DSP tipicamente suportam um variedade de modos de endereçamento e a AGU é chamada para carregar os registradores de endereço e gerar os ponteiros apropriados para endereçamento indexado (para acesso a tabelas de ondas e arrays), endereçamento em módulo (para acesso a lookup tables de osciladores), e endereçamento bit-reversal usado na computação de FFT (Fast Fourier Transform).
2.3.3.4. Floating-Point
Unit (FPU)
Num microprocessador que trata dados em ponto flutuante, essa é a ‘máquina’ do processamento digital de sinais. Ela executa operações de ponto flutuante em alta velocidade. A FPU é geralmente separada da ALU a fim de permitir execução paralela das duas unidades.
2.3.3.5. Registradores
Os registradores são tais como são apresentados em um processador de uso genérico. Normalmente são divididos entre registradores de instruções, de dados e de endereçamento.
2.3.3.6. Memória RAM
A memória RAM é acessada por operações de load store. A maioria das RAMs permitem apenas uma operação por vez. Entretanto, uma dual-ported RAM permite duas operações por vez. Muitas vezes, as memórias são dedicadas a uma função específica, por exemplo: memória de instruções e memória de dados. Essa divisão em memórias diferentes resulta num aumento de velocidade à medida que suporta que ambas as memórias sejam acessadas em paralelo.
2.3.3.7. ROM e EPROM
São geralmente utilizadas para implementar sistemas DSP estáticos tais como sintetizadores.
2.3.3.8. Shifters
e Rotators
Eles deslocam uma palavra à esquerda ou à direita. Essa categoria inclui tanto dispositivos paralelos quanto seriais. Um shifter (ou barrel shifter) shifta uma palavra um determinado número de bits à esquerda ou à direita. Rotators também shiftam as palavras tal como o shifter, com a diferença de que o bit shiftado para fora num extremo é inserido no outro extremo da palavra. Shifters são extremamente necessários para multiplicações em ponto flutuante, endereçamento fracionado e outras aplicações conde palavras são “packed” e “unpacked” em pedaços num determinado tempo. Shifters e rotators são comumente implementados internamente à ALU, AGU ou FPU.
2.3.3.9. Contadores
São incrementados à taxa do clock e emitem um sinal quando o limite for alcançado. Em geral, esse limite é programável.
2.3.3.10. DAC e ADC
São as unidades responsáveis pela conversão dos sinais do domínio analógico para o digital e vice-versa. São peça indispensável para qualquer arquitetura DSP.
2.3.4.
Fractional Addressing (endereçamento
fracionado)
Suporte de hardware para endereçamento fracionado é desejável em aplicações de processamento de sinal, particularmente em algoritmos baseados em Table lookup tais como osciladores. Um microprocessador com endereçamento fracionado pode manter um valor mais preciso para o índice de fase usado em algoritmos com table lookup a partir do momento em que mantém tanto uma parte inteira quanto uma parte fracionada do endereço da tabela. Se a o local preciso da próxima amostra é 510.7, por exemplo, um sistema sem endereçamento fracionado irá ignorar a parte fracionada e resgatar o item 510. Para apenas uma amostra essa distorção pode não ter muito efeito, mas para toda uma computação isso pode ser desastroso. Um algoritmo de interpolação, pode se aproveitar do endereçamento fracionado para tornar ainda mais preciso o cálculo da próxima amostra.
2.3.5. A questão do Branching
Instruções de Branch condicionais (por exemplo, if..then..else.. ) são básicos para qualquer processador de uso genérico. Em DSPs, que são otimizados para loops repetitivos, a questão de como implementar o branching tem sido um problema maior. Antigamente, para fins de sincronização, não eram permitidas instruções de branch em DSPs. Outro grande problema do branch é como tratar computações em unidades funcionais com pipeline.
Uma técnica clássica para se tratar jumps é prover um buffer antes do DAC e depois do ADC. Esses buffers de memória armazenavam as amostras para conversão subsequente; permitindo ao DSP um intervalo ao processar um conjunto de amostras com rotinas de tamanho variado. Entretanto, quando o buffer é muito grande, isso pode causar um atraso entre as entradas e no som resultante.
2.3.6. Paralelismo e pipeline em um DSP de um único chip
Alta velocidade pode ser alcançada com o uso interno de paralelismo e pipeline. Paralelismo usualmente se refere a operação simultânea de várias unidades funcionais, por exemplo, uma adição, uma multiplicação e um acesso a table lookup ao mesmo tempo.
Pipeline é operação concorrente em uma única unidade funcional. Uma multiplicação, por exemplo, pode requerer vários passos, tomando, assim, vários ciclos de clock. Em DSPs, as unidades funcionais possuem pipeline internos, que permitem uma melhora substancial na performance do processador. Interrupções de tempo real em intervalos regulares também tornam óbvio as vantagens do pipeline. Quando uma interrupção ocorre, o pipeline deve ser esvaziado e todas as computações em estado intermediário devem ser reiniciadas.
2.3.7.
O problema da atualização de parâmetros
Considere um DSP que executa uma função de mixagem. Ligado ao DSP está um console com centenas de botões, pinos e alavancas. Quando um controle é mudado, seja da memória ou por um gesto do engenheiro de som, o valor deve ser atualizado no DSP. Essa é a atualização de parâmetro. Um problema que os desenvolvedores de DSP encaram é definir como atualizar o DSP de uma maneira tal que o dispositivo permanece precisamente sincronizado no tempo. É necessário, para se definir o fluxo de dados em um sistema DSP, determinar o burst rate, que é a freqüência de eventos que ocorrem de uma só vez. Para resolver o problema da atualização de parâmetros tem-se dois métodos:
·
Criar
um período de atualização, que permitiria ao sistema anexar código ao cálculo
da próxima amostra.
·
Implementar
um Controlador DSP (solução mais utilizada para tempo-real), que insere um
controlador entre o DSP e o Host de
modo a reduzir a quantidade de comunicação dirigida por interrupção.
2.3.8. Microprogramando um DSP
No nível mais baixo de programação DSPs podem ser programados por microcódigo. Em alguns DSPs, cada instrução é implementada em um circuito diferente desenvolvido para enviar os devidos sinais de controle para as diferentes partes do processador. Esse tipo de sistema é chamado hardwired system.
Um DSP microprogramável é mais flexível que um circuito hardwired. Num sistema microprogramado o controle de informações para cada instrução é armazenado na memória de microprogramação, que armazena as microinstruções.
A principal vantagem da micro programação sobre circuitos hardwired é a flexibilidade. O desenvolvimento de microprogramas complexos geralmente é mais rápido que o desenvolvimento de um sistema correspondente em hardwire. A flexibilidade do microcódigo permite que instruções especiais sejam adicionadas mesmo após o término do desenho básico do sistema. Outra vantagem do microprograma é que, em circuitos hardwire, a complexidade dos algoritmos que podem ser implementados é limitada pela tecnologia usada para se criar o chip.
Entretanto, nem todos os DSPs usam microprogramação. Lógica hardwire pode ser muito mais rápida que uma dada implementação microprogramada do mesmo conjunto de instruções.
2.3.9. Array processors
Um Array Processor (AP) é um tipo especial de uma arquitetura DSP multiprocessada paralela. APs são desenhados para aplicações científicas tais como processamento de imagem, mas eles podem ser também adaptados para aplicações musicais. APs executam operações de um array ou bloco de dados de uma só vez. Por exemplo, uma operação padrão em um AP é multiplicação de arrays. A arquitetura AP faz uso intensivo de técnicas de paralelismo e pipelining que fazem com que sua arquitetura especializada atinja uma performance bem superior à de qualquer processador comum ou DSP serial.
Para computações simples, entretanto, a taxa de melhora de uma computação raramente ultrapassa 40%. Isso se deve ao fato de que APs dependem da natureza do problema e lidam com eficiência do programa escrito para resolvê-lo.
2.3.10. Arquiteturas multiprocessadas
Muitas vezes, ao se desenhar um sistema DSP se faz necessário utilizar mais elementos de processamento (EP) para melhorar a performance do DSP como um todo. Esses EPs devem ser idênticos. A comunicação entres os EP, em geral, se faz através de um cross bar switch chamado connection matrix, conforme a Figura 4.
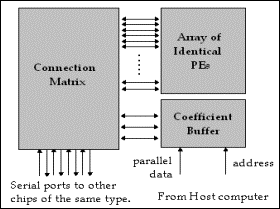
Figura 4 – Exemplo de arquitetura multiprocessada
2.4. Software
2.4.1. A Família TMS320C 5x e 8x
2.4.1.1. Série TMS320C5x Fixed Point DSP
A geraçãoTMS320C5x de processadores digitais de sinal (DSPs) da família TMS320 da Texas Instruments é fabricada com a tecnologia estática de circuito integrado CMOS. A combinação da avançada arquitetura Harvard, periféricos on-chip, memória on-chip e um set de instruções altamente especializado é a base da flexibilidade operacional e velocidade dos dispositivos C5x, que executam acima de 50 milhões de instruções por segundo.
Além disso, os dispositivos C5x apresentam as seguintes vantagens:
· Design na arquitetura que aumenta a performance e a versatilidade;
· Design modular na arquitetura para rápido desenvolvimento dos dispositivos spin-off;
· Alta performance devido à avançada tecnologia de circuito integrado de processamento;
· Set de instruções apropriados para algoritmos mais rápidos e para alto nível de linguagem de operação otimizada;
· Novas técnicas de design estático para minimizar o consumo e maximizar as tolerâncias de radiação.
2.4.1.1.1. Principais Características
· CPU de alta performance 16Bits TMS320C5x
· 20, 25, 35 e 50ns para execução de um ciclo de instrução com operação em 5V;
· 25, 40 e 50ns para execução de um ciclo de instrução com operação em 3V;
· Ciclo único 16 × 16Bits Multiplicação/Adição;
· 224K × 16Bits Espaço máximo de memória endereçável (64K Programa, 64K Dados, 64K I/O, and 32K Global);
· 2K, 4K, 8K, 16K, 32K × 16Bits Acesso Único Programa On-Chip ROM;
· 1K, 3K, 6K, 9K × 16Bits Acesso Único Programa On-Chip/ Dados RAM (SARAM);
· 1K de Memória de Programa de Acesso Dual On-Chip / Dados RAM (DARAM);
· Porta Serial Full-Duplex Síncrona para Interface Coder/Decoder;
· Porta Serial com Divisão de Tempo Multiplexada (TDM);
· Hardware ou Software com capacidade de geração Wait-State;
· Timer On-Chip para operações de controle;
· Instruções de Repeat para o uso eficiente do Espaço de Programa
· Porat Serial Bufferizada;
· Interface Host Port;
· Múltiplas opções de clock Phase-Locked Loop (PLL) (×1, ×2, ×3, ×4, ×5, ×9 dependendo do dispositivo);
· Blocos móveis para Dados/Programa de Gerenciamento;
· Lógica de emulação On-Chip baseada em Scan;
· Scan delimitado;
· Cinco pacotes de opções:
· 100-Pin Quad Flat Package (PJ Suffix)
· 100-Pin Thin Quad Flat Package (PZ Suffix)
· 128-Pin Thin Quad Flat Package (PBK Suffix)
· 132-Pin Quad Flat Package (PQ Suffix)
· 144-Pin Thin Quad Flat Package (PGE Suffix);
· Modos Low Power Dissipation and Power-Down:
· 47 mA (2.35 mA/ MIP) a 5 V, 40-MHz Clock (Média)
· 23 mA (1.15 mA/ MIP) a 3 V, 40-MHz Clock (Média)
· 10 mA a 5 V, 40-MHz Clock (Modo IDLE1)
· 3 mA a 5 V, 40-MHz Clock (Modo IDLE2)
· 5 mA a 5 V, Clocks Off (Modo IDLE2)
· Tecnologia Estática CMOS de Alta Performance;
· Padrão IEEE 1149.1 Porta de Acesso para Teste (JTAG).
2.4.1.1..2. Datasheets
Link para dowmload no formato PDF: sprs030a.pdf
(1259 KB)
Link para dowmload no formato PSZ: sprs030a.psz
(1163 KB)
2.4.1.1..3. Aplicações
Veja as diversas aplicações do TMS320C5x nos seguintes links:
· A DSP GMSK MODEM FOR MOBITEX AND OTHER WIRELESS INFRASTRUCTURES (SPRA139)
· A MULTI-SIGNAL PROC SYS FOR HIGH-SPEED MONITORING-FACTS EQUIP-ELEC POWER SYS-C50 (SPRA313)
· A PCMCIA TMS320 DSP MEDIACARD FOR SOUND AND FAX/MODEM APPLICATIONS (SPRA052)
· A SENSORLESS BRUSHLESS DC MOTOR PHASE ADVANCE ACTUATOR BASED ON THE TMS320C50 (SPRA324)
· A TMS320C50-BASED ALGORITHM CONTROL (SPRA329)
· AUTOMATED DIALING OF CELLULAR TELEPHONES USING SPEECH RECOGNITION (SPRA144)
· CALCULATION OF TMS320C5X POWER DISSIPATION (SPRA030)
· CHANNEL EQUALIZATION FOR THE IS-54 DIGITAL CELLULAR SYSTEM WITH THE TMS320C5X (SPRA141)
· DESIGN OF ACTIVE NOISE CONTROL SYSTEMS WITH THE TMS320 FAMILY (SPRA042)
· DESIGNING AN AUDIOPROCESSOR FOR AUTOMOBILES WITH THE TMS320C50 DSP (SPRA302)
· DESIGNING AN ECHO CANCELLER SYSTEM USING THE TMS320C50 DSP (SPRA322)
· DESIGNING TEACHING MATERIALS FOR DSPS BASED ON THE TMS320C50 DSP (SPRA346)
· DEVELOPING SECURE COMMUNICATION SYSTEMS USING THE TMS320C50 DSP (SPRA318)
· DIGITAL MONOPULSE DOPPLER RADAR AND DSP TEACHING (SPRA342)
· DIGITAL VOICE ECHO CANCELER IMPLEMENTATION ON THE TMS320C5X (SPRA142)
· DSP-BASED HANDPRINTED CHARACTER RECOGNITION (SPRA143)
· ELECTROSTATIC DISCHARGE APPLICATION NOTE (SSYA008)
· EMULATION FUNDAMENTALS FOR TI'S DSP SOLUTIONS (SPRA439)
· ENHANCED CONTROL OF AN ALTERNATING CURRENT MOTOR USING FUZZY LOGIC (SPRA057)
· EQUALIZATION CONCEPTS: A TUTORIAL (SPRA140)
· FRONT-END PROCESSING FOR MONOPULSE DOPPLER RADAR (SPRA299)
· IMPLEMENTING A PI/4 SHIFT D-QPSK BASEBAND MODEM USING THE TMS320C50 (SPRA341)
· IMPLEMENTING ADAPTIVE PREDICTIVE CONTROL WITH THE TMS320C50 DSP (SPRA311)
· IMPROVING 32-CHANNEL DTMF DECODERS IN PBX SYSTEMS USING THE TMS320C5X DSP (SPRA085)
· INTERFACING THE TLV1544 ANALOG-TO-DIGITAL CONVERTER TO THE TMS320C50 DSP (SLAA025A)
· IS-54 DIGITAL CELLULAR MODEM IMPLEMENTATION ON THE TMS320C5X (SPRA138)
· LINKING C DATA OBJECTS SEPARATE FROM THE .BSS SECTION (SPRA258)
· MINIMIZING QUANTIZATION EFFECTS USING THE TMS320 DSP FAMILY (SPRA035)
· SEARCHING FOR THE BEST QUADRIPHASE CODES USING THE TMS320C50 DSK (SPRA300)
· SETTING UP TMS320 DSP INTERRUPTS IN 'C' (SPRA036)
· SINGLE CHANNEL ACTIVE ADAPTIVE NOISE CANCELLER WITH THE TMS320C50 STARTER KIT (SPRA285)
· SOFTWARE CODING GUIDELINES FOR TMS320C5X DEVELOPERS (SPRA149)
· SPEAKER INDEPENDENT SPEECH RECOGNITION ON THE TMS320C2X AND TMS320C5X DSPS (SPRA100)
· TCM320AC3X/4X VOICE-BAND AUDIO PROCESSORS (SPRA146)
· TEACHING DSP THROUGH THE PRACTICAL CASE STUDY OF AN FSK MODEM (SPRA347)
· TELECOMMUNICATIONS APPLICATIONS WITH THE TMS320C5X (SPRA033)
· THE EXPRESSDSP ALGORITHM STANDARD (SPRA581)
· THEORY & IMPLEMENT OF DIGITAL CELLULAR STD VOICE CODER: VSELP ON THE TMS320C5X (SPRA136)
· U.S. DIGITAL CELLULAR ERROR-CORRECTION CODING ALGORITHM ON TMS320C5X DSPS (SPRA137)
· USE OF THE TMS320C5X INTERNAL OSCILLATOR WITH EXTERNAL CRYSTALS OR RESONATORS (SPRA054)
· V.34 TRANSMITTER AND RECEIVER IMPLEMENTATION ON THE TMS320C50 DSP (SPRA159)
VITERBI
IMPLEMENTATION ON THE TMS320C5X FOR V.32 MODEMS (SPRA099)
2.4.1.1.4. Manuais do usuário
Veja os manuais do usuário do TMS320C5x nos seguintes links:
· FIXED-POINT DSP ASSEMBLY LANGUAGE TOOLS USER'S GUIDE (SPRU018D)
· MANUAL UPDATE SHEET FOR TMS320C5X USER'S GUIDE (UPDATING SPRU056C) (SPRZ113A)
· PARALLEL DEBUG MGR ADDENDUM TO TMS320C4X AND TMS320C5X C SOURCE DEBUGGER UG (SPRU094)
· TMS320 DSP DEVELOPMENT SUPPORT REFERENCE GUIDE (SPRU011F)
· TMS320C2X/C2XX/C5X OPTIMIZING C COMPILER USER'S GUIDE (SPRU024E, 566 KB)
· TMS320C54X DSK PLUS ADAPTER KIT (SLAU030, 581 KB)
· TMS320C5X C SOURCE DEBUGGER USER'S GUIDE (SPRU055B)
· TMS320C5X DSP STARTER KIT USER'S GUIDE (SPRU101A)
· TMS320C5X EMULATOR GETTING STARTED GUIDE (SPRU196)
· TMS320C5X EMULATOR INSTALLATION GUIDE (SPRU125B)
· TMS320C5X EVALUATION MODULE INSTALLATION GUIDE (SPRU126C)
· TMS320C5X GENERAL-PURPOSE APPLICATIONS USER'S GUIDE (SPRU164)
TMS320C5X SIMULATOR GETTING STARTED GUIDE (SPRU124C)
2.4.1.2. Normandy (Tecnologia da National compatível
com TMS320C5X)
Com o objetivo de integrar plataformas multi-core destinada a área de telecomunicações, sem a necessidade de reescrever código assembler, o que atrasa o lançamento de produtos no mercado, a National criou um componente denominado Normandy. Com este chip, a National enfocou o uso de processadores padrão integrados em um sistema de software paralelo amigável. Esta integração inclui dois elementos:
· uma unidade inter-core de comunicação (ICCU), que disponibiliza um espaço de endereçamento unificado para os processadores, controle de interrupção e semáforos;
· um ambiente multi-core para debug.
O ambiente de debug suporta o debug de cada core sem causar impacto em outros cores, não necessitando parar os diversos cores ao mesmo tempo.
Normandy resolve o acoplamento do microprocessador com o DSP sem diminuir a velocidade de desenvolvimento do software. O Normandy é composto por dois DSPs Emerald (compatíveis com TMS320C5X) e um CR 32, um core RISC CompactRISC 32 bits. O poder de processamento é suportado pela unidade inter-core de comunicação (ICCU), memória local para cada processador, controlador USB, interface ISA, interface AFE, funções de gerenciamento de energia, unidade de controle de interrupção, 16 canais de DMA, vários timers, WATCHDOG e uma porta JTAG comum para debug.
Cada um dos processadores possui um barramento local com recursos locais (memória e periféricos). Isto localiza o tráfego de memória do processador permitindo a operação paralela (full-parallel), maximizando a performance geral do sistema. Esta ICCU faz a ponte entre os processadores permitindo o acesso a outros processadores ou recursos do barramento local. Isto permite flexibilidade na alocação dos recursos de sistema para as diferentes tarefas, simplificando o modelo de programação.
Um sistema baseado no Normandy pode possuir até cinco dispositivos externos codificados. Dois deles podem ser modems codificadores-decodificadores de alta qualidade. Os restantes três são codificadores-decodificadores PCM. Estes codificados PCM são usados para I/O de voz PCM com qualidade. O código e os dados são armazenados em uma DRAM conectada ao barramento externo do CompactRISC ou a dois dispositivos SRAM conectados ao barramento externo do DSP. Uma EEPROM ou um dispositivo flash serial é usado para manter a informação de configuração, conforme mostra a Figura 10.
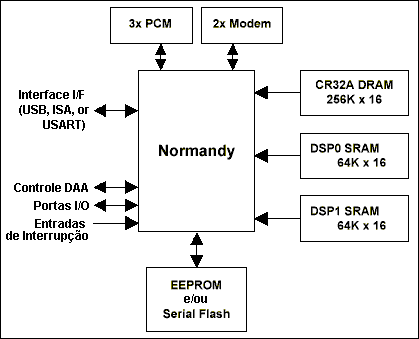
Figura 10 - Diagrama em Blocos do Sistema Normandy
A memória e os dispositivos de I/O são diretamente mapeados em 4Gbyte de endereços CompactRISC. Isto inclui código, dados e periféricos para ambos Emeralds e o barramento CompactRisc.
O Emerald é compatível com TMS320C5X– popular família de processadores DSP da Texas Instruments já descrita neste trabalho. Sendo assim suporta o conjunto de instruções completo destes DSPs e é compatível ciclo-a-ciclo em termos de execução de instrução.
Uma aplicação adequada ao Normandy é um telefone residencial Voice Over IP (VoIP), chamado também de “Internet Phone”.
Com um telefone VoIP, quando o usuário disca um número de longa distância ao invés de conectar-se a rede pública de transporte, o fone automaticamente conecta-se a um Provedor de Serviço Internet (ISP - Internet Service Provider). Após estar conectado ao ISP, a conversação de voz é transmitida via TCP/IP usando os padrões ITU de protocolo através da internet.
A combinação de cores padrão e periféricos torna o Normandy adequado a aplicações destinadas a multimídia, comunicação de grande velocidade e várias outras aplicações. A capacidade de possuir mais de um DSP em um simples chip, e possuir um ambiente de debug acoplado é um grande passo nas necessidades para os engenheiros de sistemas de hoje em dia.
2.4.1.3. Série TMS320C8x
Multiprocessor DSP
A série C8x tem poder de processamento para suportar aplicações que requeiram alta performance para processamento digital de sinais .
A família tem dois membros. O C80 é um único chip com processador paralelo que pode ser usado para aplicações como processamento de áudio/vídeo em tempo real, comunicações de dados high-end e processamento de imagens. O C82 é o outro membro da série que pode ser usado em aplicações de alto volume de processamento como videoconferência , comunicações em alta velocidade e gráficos tridimensionais .
A série C8x possui dispositivos altamente programáveis , sendo que neles podemos agregar algoritmos industriais padrões com softwares proprietários para otimizar a performance e diferenciação de produtos no mercado . Recebemos flexibilidade adicional pois esses sistemas podem ser adaptados através de modificações de software . Isso possibilita um upgrade aos novos padrões emergentes .
Suas principais características são:
·
Versão
capaz de efetuar 2 bilhões de operações por segundo;
·
Performance
em 40,50,60 Mhz;.
·
Processador
mestre RISC de 32 bits com unidade de ponto flutuante IEEE-754 integrada;
·
Processadores
paralelos de 32 bits (DSPs avançados ) com palavras de instrução de 64 bits:
Ø 4 processadores paralelos no
C80 e 2 processadores paralelos no C82.
·
50
Kb de RAM interna no C80 e 44 Kb de RAM interna no C82;
·
Um crossbar
on-chip que permite múltiplos instruction
fetches e acessos de dados paralelos durante cada ciclo para suportar altas
taxas de transferência:
Ø Acima de 4,2Gb/s no C80;
Ø Acima de 2,6 Gb/s no C82.
·
Modo
de byte ordering litlle-endian e big-endian suportados;
·
Espaço
de endereçamento de memória de 4Gbyte;
·
Capacidade
de transferência de controle de 64-bits acima de 400 Mbytes /s dentro e fora do
chip:
Ø Dynamic sizing de largura do barramento (64,32,16 ou 8 bits);
Ø Acesso direto a memórias VRAM/DRAM/SRAM/SDRAM de 64 bits;
Ø Acesso direto a extended
data out (EDO) DRAM de 64 bits (C82).
·
Controlador
de vídeo que contém temporizadores dual-frame
para a captura e visualização de imagens simultaneamente (C80 apenas );
·
Quatro
interrupções externas;
·
Um
design full-scan (mais boundary-scan) acesso via um padrão IEEE
1149 , 1 (JTAG) porta de teste que da suporte a emulação;
·
TI
EPIC 0,5 micro tecnologia CMOS;
·
Empacotamento
eficiente:
Ø Ceramic pin grid array (CPGA) de 305-pinos ou 352 ceramic bali grid array (CBGA)
C80 352 ball-grid array (BGA)
(C82).
2.4.2. Processador Master (MP)
É um processador RISC com uma unidade de ponto flutuante IEEE-754 integrada, de acordo com o esquema mostrado na Figura 5. Como nos demais processadores RISC todos os acessos a memória são feitos por instruções de load / store ,e a maioria das operações lógicas e inteiras são feitas em registradores em um único ciclo .Ocorre o pipeline para instruções de ponto flutuante, portanto, podemos iniciar uma multiplicação de precisão simples ou uma adição de ponto flutuante a cada ciclo de clock.
As operações de ponto flutuante usam o mesmo arquivo de registradores que as unidades lógica e inteira. Um scoreboard de registrador garante que seqüências de acessos a registradores corretas sejam mantidas.
O MP é estruturado para a execução eficiente de um código C . Por exemplo, o MP contém um registrador, geralmente chamado zerador, usado pelo C. Também, o conjunto de instruções do MP é feito sob medida para conter muitos dos códigos executáveis C encontrados em tecnologia dos compiladores C.
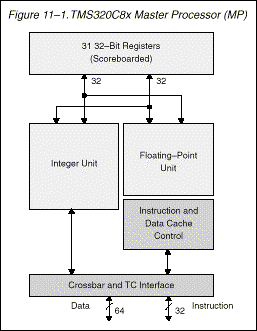
Figura 5 - Processador Master
As características do Processador Master incluem :
·
CPU
RISC de 32bits 60 MHz:
Ø Projetadas para linguagens
de alto nível.
·
Unidades
de ponto flutuante IEEE-754:
Ø Multiplicação , adição e load/store paralelos.
·
31
registradores de 32 bits:
Ø Fila de registradores única
para inteiros e ponto flutuante;
Ø Loas e os resultados da FPU
são colocados no scoreboard.
·
Cache
de controle para instruções e dados:
Ø Cache de instrução de 4Kbytes;
Ø Cache de dados de 4Kbytes;
Ø RAM paramétrica de 2
Kbytes (C80);
Ø RAM paramétrica de 4 Kbytes
(C82).
2.4.2.1. A unidade de ponto flutuante
É capaz de fazer operações de ponto flutuante (IEEE-754 ) em precisão simples (32 bits) e dupla (64 bits) . São suportadas conversões entre os dois formatos . Na adição , a FPU providencia um vetor operações de ponto flutuante com a opção de fazer operação de load/store para aumentar a eficiência dos programas .
O suporte de hardware para a FPU consiste de um somador completo de dupla precisão de ponto flutuante .e um multiplicador de 32 bits de ponto flutuante de precisão simples .
2.4.2.2. Características da FPU do
Processador Master
A seguir são descritas as características da FPU (Floating -Point Unit ) ilustrada no esquema da Figura 6:
·
Ponto
flutuante IEEE-754;
·
Tratamento
de exceções de hardware;
·
Adição
de ponto flutuante com ALU de precisão dupla:
Ø Comparações, subtrações e
adições de um único ciclo (simples e dupla precisão ) e conversões;
Ø Divisão em precisão simples
em seis ciclos e em precisão dupla com 20 ciclos;
Ø Raiz quadrada em precisão
simples em nove ciclos e em precisão dupla com 26 ciclos.
·
A
Unidade de multiplicação de ponto flutuante faz todas as multiplicações
(inteiras e de ponto flutuante), divisões e raiz quadrada:
Ø Multiplicação de precisão
simples em um ciclo;
Ø Multiplicação de dupla
precisão em quatro ciclos.
·
Pipelined – pode-se iniciar uma nova
instrução a cada ciclo:
Ø Pipeline de 3 estágios;
Ø Scoreboard da fila de registradores previne
“races”.
·
Vetor
de ponto flutuante para 120 MFLOP:
Ø Multiplicação paralela ,
adição e load 64 bits em um ciclo;
Ø Suporta pipeline para quatro somadores de dupla precisão;
Ø Suporta multiplicação de
matrizes.
·
Registradores
FP de estado e interrupt-enable:
Ø Instruções de test-and-branch do Processador Master
acessam o registrador de estado do FP.
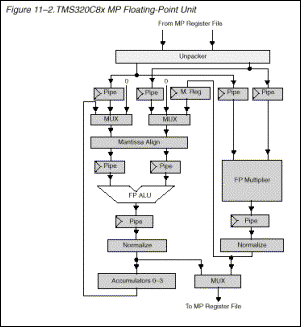
Figura 6 -
FPU (Floating-Point Unit)
2.4.3.
DSPs de Processamento Paralelo Avançado (PP)
Muito do poder do C8x é proporcionado pelo processador digital de sinais de processamento paralelo avançado . Os PPs são desenhados para fazer o processamento digital de sinais através dos campos de bit e manipulação de múltiplos pixels . Estes processadores tem características avançadas que não são encontradas em outros DSPs ou em processadores de propósito geral e fazer operações RISC-like em excesso de dez em cada ciclo .
Para especificar as múltiplas operações paralelas que os PPs podem fazer , uma palavra larga de 64 bits é usada . A instrução tem campos que controlam independentemente a unidade de dados e unidades de dois endereços . Todas as instruções executam em um mínimo de um único ciclo .
Cada PP tem uma fila de registradores de 44 registradores visíveis ao usuário . Todos os registradores podem ser a fonte ou o destino das operações de ALU e memória.
O conjunto de registradores é dividido em filas de acordo com a função de cada registrador.
Os PP’s apresentam as seguintes características, conforme Figura 7:
·
ALU
de três entradas com operações aritméticas e booleanas misturadas:
Ø Fazem mascaramento de uma
adição ou subtração.
·
Data-path feeding flexível ALU de 3 entradas;
·
Fast bit e processamento de campo;
·
Caminhos
de dados dos endereços pode ser usados para aritmética de propósito geral;
·
Múltipla
aritmética Byte / halfword:
Ø Fluxo único de instruções,
fluxo múltiplo de dados processados com cada processador;
Ø Melhor tratamento de pixels
e buffers Z que em outros DSPs ou
GPPs.
·
Oito
registradores de dados primários , d0 a d7 (Registradores D) , que podem
realizar acima de sete leituras e 4 escritas:
Ø Duas fontes multiplicadoras
, três fontes de ALU, um resultado de multiplicador , um resultado de ALU e
três LD/ST/MOVE.
·
Multiplicador
divisível para caminho de rápido de
pixel;
·
Três
níveis de loops de overhead zero;
·
Operações
condicionais (para ALU, load/store, and/or de fonte de
registrador );
·
Características
adicionais;
·
Duas
unidades de endereço:
Ø Acima de duas operações de
memória por ciclo.
·
Multiplicador
de ciclo único:
Ø Um resultado de 16 bits ou
dois de 8 bits por ciclo.
·
ALU
de três entradas divisível:
Ø Múltiplos operandos em cada
passo;
Ø Acima de quatro resultados
de 8 bits por ciclo.
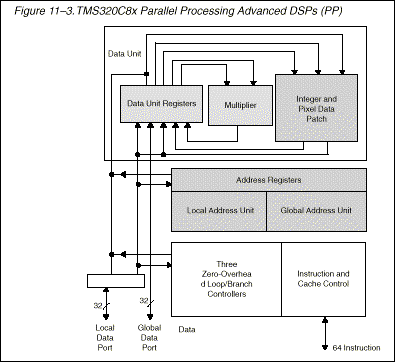
Figura 7 - PP (Parallel Processing
Advanced)
2.4.4.
Controlador de Transferências (TC - Transfer
Controller)
O controlador de transferências (TC) é um combinado de máquina DMA e interface de memória que inteligentemente escalona, prioriza, e responde aos requisitos de dados e faltas em cache do MP e PPs. O controlador de transferências interage diretamente com as SRAMs internas. Através do TC, todos os processadores podem acessar o sistema externo ao chip. Além disso, as faltas em cache de dados ou instruções são automaticamente tratados pelo TC.
Transferência de dados são especificamente requisitadas pelos PPs ou pelo MP na forma de transferências de listas interligadas de pacotes, as quais são tratadas pelo TC. Estas requisições permitem blocos multidimensionais de informação serem transferidas entre uma fonte e o destino, que podem ser on-chip ou off-chip. Transferências de dados orientada por pacotes oferecem compatibilidade com várias redes de áreas locais normais, tais como redes ATM. O TC realiza:
·
Preenchimento
de cache e escritas;
·
Loads e stores diretos de/para memória externa ao chip através de requisição DEA;
·
Movimentação
de blocos de dados através de transferências de pacotes;
·
Ciclos
de refresh e SRT(Shift Register Transfer) necessários para manter DRAMs e buffer de captura/display VRAM, respectivamente;
·
As
características do TC incluem:
Ø 400 Mbytes/s de bandwidth externa;
Ø Controle direto de RAM,
VRAM, SRAM e SDRAM, EDO DRAM (C82);
Ø Ajuste dinâmico do tamanho
do barramento (64, 32, 16, ou 8 bits);
Ø Transferência de pacotes
controladas autonomamente pelo controlador de transferências;
Ø Endereçamento linear x/y;
Ø Fonte e destino
independentes;
Ø Alinhamento automático de
bytes;
Ø Requisição inteligente (escalonamento e priorização).
O TC do C82 inclui um cache de configuração de memória que consiste de seis palavras de 32 bits que descrevem as propriedades dos seis bancos de memória mais recentemente usados. O cache automaticamente carrega as palavras de configuração cada vez que um acessa a novos bancos é feito e podem ser fixados em um conjunto de alta ou baixa prioridade. O cache de configuração reduz o número de pinos necessários no C82 e em chips de suporte.
A Figura 8 mostra um diagrama de blocos do TC de um C8x.
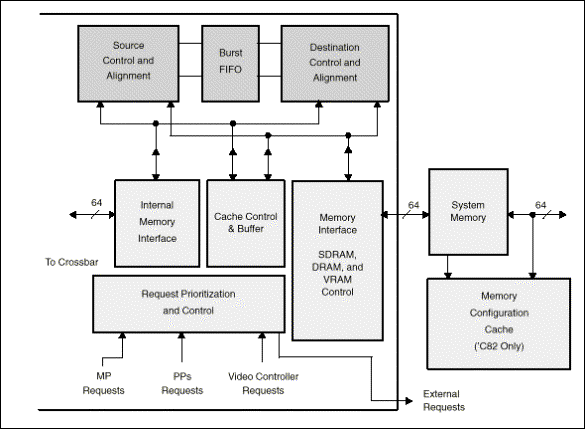
Figura 8 - Diagrama de Blocos de um TC (Transfer
Controller)
2.4.5. DSP Benchmarking
Os métodos tradicionais de benchmarking aplicados à GPP (general purpose processors) tais como MIPS ou MFLOPS não são tão significativos quando aplicados a placas DSP. Esses métodos perdem o sentido devido a grande variedade de ISAs pertinentes a diferentes placas DSP.
Apesar de a velocidade de execução ser apenas um fator na escolha de um processador, ela é de vital importância quando se precisa de alto poder de processamento como em aplicações DSP. Projetistas de sistemas DSP precisam de um fator métrico que o permita identificar os processadores que atende aos requerimentos de velocidade do seu sistema.
Um exemplo de que as medidas de MIPS e MFLOPS não significam muito em se tratando de processadores DSP está ilustrada no exemplo a seguir.
Considere o loop interno de um filtro de resposta a um impulso finito, representado matematicamente, onde x é o valor da amostragem, h é um coeficiente e y a saída do filtro.
O DSP Motorola da família 563xx implementaria essa função similar a:
move
#Xaddr,r0
; load data address into r0 pointer
move
#Haddr,r4
; load coefficient address into r4 pointer
rep
#Ntap
; repeat the next instruction Ntap times
mac x0,y0,a
x:(r0)+,x0 y:(r4)+,y0 ; multiply
and accumulate a sample and coef.
Isso porque o DSP 563xx tem um hardware dedicado a looping, dois geradores de endereço e instruções específicas para implementação do filtro. Todo o trabalho do processador basicamente se concentra na última instrução de multiplicação/acumulação (MAC), que multiplica amostra pelo coeficiente correspondente, carrega a próxima amostra e coeficiente e atualiza os ponteiros de endereço, tudo em uma instrução.
Agora considere esse mesmo algoritmo implementado na família da Texas Instruments TMS320C62xx:
loop:
ADD.L1 A0,A3,A0 ; A0=A0+A3
ADD.L2 B1,B7,B1 ; B1=B1+B7
MPYHL.M1X A2,B2,A3 ; A3=A2(hi)*B2(lo)
MPYLH.M2X A2,B2,B7 ; B7=A2(lo)*B2(hi)
LDW.D2 *B4++,B2 ; load into B2
LDW.D1 *A7--,A2 ; load into A2
ADD.S2 -1,B0,B0 ; decrement counter
[B0] B.S1 loop ; branch if B0 nonzero
A família TMS320C62xx utiliza-se de very-long-instruction-word (VLIW) architecture, que executa instruções relativamente simples em paralelo. Praticamente todas as instruções acima executam simultaneamente, e as duas operações de multiplicações executam em paralelo. Mas o número de instruções requeridas para implementar o filtro é muito maior que o Motorola DSP563xx.
O TMS320C62xx opera a 150 MHz e executa até 8 instruções por ciclo de clock, atingindo uma taxa de 1200 MIPS. Isso é bem maior que a taxa de 100 MIPS que o DSP 563xx, que roda a 100 MHz, Isso da uma proporção de 12 para 1 em favor da Texas. Mas no exemplo do filtro FIR acima, o TMS320C52xx com 200 MHz e unidade MAC dupla consegue apenas uma taxa de 3 para 1 sobre o DSP 563xx da Motorola. Em suma, MIPS e, analogamente, MFLOPS sofrem dessas falhas que os tornam inapropriados para medição de performance em DSP.
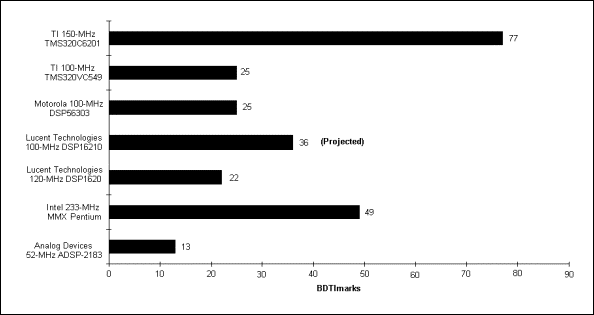
O ideal seria que um Benchmark abordasse trechos de programas ao invés de instruções isoladas. Esses trechos deveriam representar algoritmos mais comuns em aplicações DSP. Um benchmark existente no mercado é produzido pela BDTIMark e gera um gráfico claro e objetivo sobre a performance de até 11 famílias diferentes de processadores.
A limitação do BDTImark é o fato de que ele desconsidera aptidões específicas de DSPs projetados para um determinado tipo de aplicação.
Os gráficos a
seguir ilustram os resultados de benchmark
da BDTIMark para Fixed-Point e Floating-Point
DSPs.
Resultados de Fixed-Point DSPs
Resultados de Floating-Point DSPs
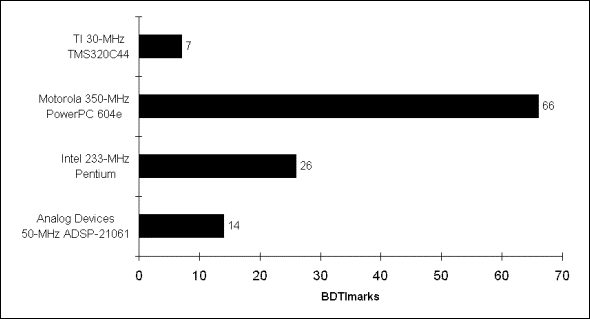
Maiores taxas de BDTIMarks indicam tempos mais rápidos de execução.
2.5. Exemplos de Aplicações com DSPs
2.5.1. Parte Prática utilizando o Starter Kit (DSK) do DSP TMS320C50
No passado, adquirir um DSP requeria um investimento de ao menos US$ 1,000 para o desenvolvimento de uma plataforma de hardware. Hoje em dia, por apenas US$ 99, tanto desenvolvedores como iniciantes podem, igualmente, entrar no mundo dos processadores digitais de tempo real.
O C5x DSP Starter Kit (DSK) consiste numa placa de 16Bits conectável ao PC através da Porta Serial. Combinando-se a placa C5x DSK com as ferramentas compilador assembler, debugger e loader e os programas de testes, tem-se um rico instrumento de desenvolvimento de códigos em tempo real.
O conteúdo do kit é o seguinte:
· placa do circuito TMS320C50;
· Software contendo C5x DSK assembler, debugger, loader, e de testes;
· Guia do usuário do TMS320C5x;
· Guia do usuário doTMS320C5x;
· Resumo do módulo de avaliação do TMS320C5x;
O dispositivo apresenta as seguintes características:
· DSP TMS320C50 40MHz;
· Um chip de interface analógica TLC32040 com resolução linear de14Bits;
· Uma porta serial RS-232 para comunicação com o PC;
· Dois conectores padrão RCA;
· Um chip PROM de 32Kbytes
· Um conector de 2.1mm para fonte de alimentação;
· Um oscilador de 40Mhz;
· Fácil expansão, com portas seriais e sinais do dispositivo disponíveis em conectores externos.
O DSK assembler difere de muitos outros dispositivos assemblers na medida em que não direciona um linker para criar um arquivo de saída. Ao invés disso, o DSK usa diretivas especiais para montar o código num endereço único durante a fase de construçào deste código. Como resultado, pode-se criar programas facilmente. Mesmo assim, este não é um assembler COFF , pode-se criar arquivos com o uso do TI TMS320 que disponibiliza ferramentas de linguagem que carregam e rodam no C5x DSK.
O DSK debugger é de fácil utilizaçào, possui uma interface orientada que reduz o tempo de aprendizado e elimina a necessidade de memorizar comandos complexos. O debugger é capaz de carregar e executar códigos com passo único, breakpoint e run-time com interrupções.
Utilizando-se o kit acima descrito, implementar-se-á um filtro digital a partir de vetores A e B, coeficientes do filtro.
Colocando-se um sinal de áudio na entrada analógica do kit, esse sinal será convertido para digital, filtrado e enviado para outra saída analógica. Essa saída alimentará uma caixa de som onde perceber-se-á a atuação do filtro sobre o áudio. Por exemplo, ligando-se um CD player na entrada, poderá obter-se na saída apenas o instrumental da música.
2.5.2. Controlador de Vídeo
(VC) com TMS320C80
O controlador de vídeo é incluído apenas na arquitetura do C80 e é a interface entre o dispositivo e os sistemas de display e captura de imagens.
O C80 tem dois conjuntos de contadores de “frame timing” e registradores. O controlador de vídeo mantém controle de sincronização horizontal e vertical e de blanking timing, assim como o suporte a região de borda bidimensional. Cada contador tem suas próprias entradas de clock assíncronas. Estes sinais de sincronização podem ser individualmente utilizadas como saídas (para display) ou entradas (para captura).
Quatro seções principais se destacam no controlador de vídeo:
·
Frame Timers
·
Controlador
de transferências seriais de registradores
·
Interface
de registradores
·
Multiplex
As características do controlador de vídeo incluem:
·
Dois
frame timers idênticos:
Ø
Podem
ser usadas para display ou captura;
Ø
Cada
um tem um clock assíncrono;
Ø
Gera
timing completamente programável na
horizontal, vertical, blank e borda.
·
Controlador
SRT:
Ø
Controla
duas regiões de display/captura;
Ø
Têm
controle de transferências de registradores de deslocamento em VRAM;
Ø
Gera
interrupções de timer ao MP;
Ø
Gera
requisições de pacotes do timer ao
TC.
A Figura 9 mostra um
diagrama de blocos do Controlador de Vídeo do C80.
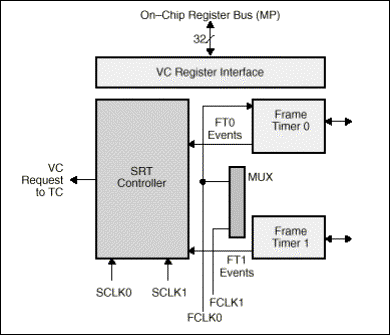
Figura 9 - Diagrama de Blocos do
Controlador de Vídeo do C80
2.6. Diferenças entre um processador de uso genérico e um
DSP
Em geral, um GPP (general purpose processor) manipula dados armazenados, enquanto um DSP é otimizado para processar sinais externos ou gerar sinais em tempo real. Os recursos específicos de arquitetura que diferenciam um DSP de um GPP incluem o seguinte:
· DSPs são otimizados para execução rápida de multiplicação com acumulação (instrução MAC, Multiply/Accumulate presente em quase todas as arquiteturas DSP). Além disso, um DSP é especializado em processamento numérico; não há instruções para processamento de strings ou caracteres.
· DSPs possuem múltiplas memórias de propósito específico, que podem ser acessadas concorrentemente. (program memory, data memory, sine table memory, high speed cache memory) Algumas memórias podem transferir bits em paralelo.
· Um DSP tem múltiplas portas de I/O e mais de um controlador de DMA (direct-access memory). Um DMA pode transferir blocos de dados sem interromper as computações correntes.
· As várias unidades funcionais de um DSP operam em paralelo, ao contrário do GPP que geralmente possui um unidade central de processamento (CPU) única.
· Um DSP possui múltiplos barramentos de alta velocidade que operam em paralelo para instruções e dados e de uma unidade funcional a um dispositivo externo.
· Um DSP possui suporte a interconexão de alta velocidade com outros DSPs do mesmo modelo numa configuração de multiprocessamento simétrico.
· Um DSP pode tratar interrupções muito rapidamente, supondo que elas são atualizações de parâmetros vindo de um porto de entrada. Ao contrário do GPP, um DSP não gastará tempo salvando o contexto do processador antes de tratar a interrupção.
A Figura 11 mostra uma comparação das arquiteturas de um processador de uso genérico e um DSP.
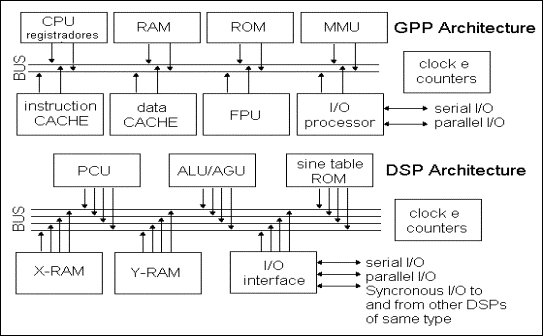
Figura 11 -
Esquema comparativo de uma arquitetura básica de um processador de uso genérico
(acima) e um DSP (abaixo). Note o
suporte a multiprocessamento e o multi-parallel bus presente no DSP.
A maioria das aplicações DSP são, por natureza, executadas em tempo-real, como, por exemplo, compressão de áudio e modems. Mesmo as aplicações que não requerem real-time execution necessitam de um alto poder de processamento e sua performance deve ser a máxima possível. Devido a esses fatos, é importante que uma placa DSP tenha as seguintes características:
· Execution Predictability
· Advanced Memory Management
· Branch Prediction
· Dynamic Instruction Scheduling
· Data-Dependent Execution Times
· Tools
Essas características são difíceis de ser encontradas em processadores de uso genérico.
Execution predictability: principalmente em aplicações de tempo real (real-time applications) é necessário que um desenvolvedor saiba de antemão o tempo de execução consumido por um determinado trecho de código, pois somente se prevendo a performance de um DSP pode-se garantir um comportamento em tempo real.
Advanced Memory Management: Por Advanced Memory Management entende-se por todo o controle exercido sobre a memória interna do DSP e a memória de um processador de uso genérico, se houver um. É necessário que o DSP possua um sistema avançado de caching e acesso à memória, porém isso apenas não basta. Para sistemas que usam um DSP aplicado a um processador de uso geral como um Pentium, por exemplo, é necessário que o aplicativo otimize ao máximo a troca de informações entre o DSP e o computador para garantir a alta performance do DSP.
Branch Prediction: Branches em processadores com pipeline pode ter um alto custo. Uma abordagem para se evitar perdas com branches é a utilização de circuitaria específica para a previsão de branches tomados. Entretanto, assim como no cache, a previsão de branch é um fator probabilístico e isso dificulta a determinação exata da performance do DSP sobre um trecho de código com branches (Execution Predictability).
Dynamic Instruction Scheduling: Para arquiteturas superescalares, o escalonamento de instruções é peça fundamental para a maximização do paralelismo de instruções.
Data-Dependent Execution Times: Alguns GPPs possuem instruções cujo tempo de execução dependem do dado. Isso significa que o tempo de execução de algumas instruções depende do valor dos operadores que estão sendo processados. Esse caso é diferente, mais tratável e mais comum que aquele em que o tempo de execução depende do tamanho dos operandos (por exemplo, double word multiply versus single word multiply). Quando instruções chaves relacionadas a DSPs possuem tempo de execução dependente dos dados, o trabalho de estimar o tempo de execução se torna mais complicado. Uma abordagem conservadora para se prever a performance do código é, na presença de tempo de execução dependente de dados se assume o máximo tempo para cada instrução. Isso pode resultar numa previsão irreal e pessimista de algumas aplicações. Em alguns casos pode-se determinar os limites do operando e, assim, se obter uma previsão mais realista. Na verdade, esse processo é complexo e não prático. Para GPPs sofisticados, o que se faz é executar o código e medir seu tempo de execução. Esse medida também não é satisfatória, já que não exibe o pior caso.
Tools: Para se desenvolver aplicações em tempo real, a maioria dos fabricantes de DSP possuem ferramentas de desenvolvimento que permitem otimização e debugging a nível de instrução. Essas ferramentas são extremamente avançadas e possibilitam ao desenvolvedor visualizar todo o caminho de execução da sua aplicação. Esse tipo de ferramenta não está presente para processadores de uso genérico.
2.7. Desenvolvimento de sistemas DSP
O desenvolvimento de sistemas DSPs tem se popularizado muito, não só pela imensa aplicabilidade que os processadores proporcionam mas pelas ferramentas de desenvolvimento avançadas que surgiram no mercado. Atualmente todos os fabricantes de DSPs possuem um kit de desenvolvimento que permite a produção de software em Assembly proprietário ou C. Existem ainda no mercado Starter Kits (kits para iniciantes) que incluem processadores, placas e ferramentas de desenvolvimento que introduzem usuários iniciantes no universo do processamento digital de sinais.
Ferramentas de desenvolvimento mais avançadas (e mais caras) incluem Debuggers, que permitem depuração de código e visualização de contexto a nível de instruções. Debuggers escritos para processadores paralelos permitem tratar cada processador em separado, possibilitando um enorme poder de depuração jamais encontrado para processadores de uso genérico. Simuladores possuem a capacidade de simular aplicações de tempo real e fazer previsão de tempo de execução. Há ainda disponível no mercado ferramentas destinadas à otimização de código para determinados tipos de computação.
Códigos de computações típicas de DSPs tais como filtros e FFT podem ser encontrados na Internet, nas categorias de freeware ou shareware. O grupo comp.dsp é um grupo de notícias destinado a tirar dúvidas de desenvolvedores desde o processo de escolha do DSPs até a implementação de algoritmos para uma plataforma específica. Esse grupo pode ser muito útil e foi importante fonte de informação para a confecção desse material.
As ferramentas de desenvolvimento descritas acima estão disponíveis nas mais diversas plataformas e os preços variam de acordo com a plataforma escolhida. Utilizando a linha da Texas Instruments como exemplo, temos os custos abaixo: (todas as ferramentas estão disponíveis para Windows NT, SunOs e HP sendo as ferramentas para Windows NT as mais baratas e as versões para SunOs as mais caras
· Compilador Assembly/C (com biblioteca real-time): $2500-$4000
· Ambientes de desenvolvimento
(dev kits)
· IDE (integrated development environment)
· Debugger
· Emuladores / Simuladores:
$500-$1000
· DSP TMS320C6201: $96-$200
O custo médio de desenvolvimento de uma aplicação DSP é impossível de ser determinado devido a grande variedade de aplicações bem como tipos de processadores, que variam de $10 a $400. Podemos citar o exemplo de que uma placa aceleradora de vídeo para processamento de gráficos em três dimensões utilizando o TMS320C80 que foi descrito nessa documentação que tem seu preço variando de $1900 a $2500, dependendo da configuração.
2.8. Mercado
O
mercado de DSP é um leque aberto para desenvolvedores pois fornece um sem
número de aplicações específicas que alcançam nichos ainda pouco explorados.
Pesquisas de mercado indicam que, em volume de dinheiro, os mercados mais
promissores para DSPs são: telefonia celular digital, pagers e outras aplicações wireless,
modems, hard-disk server control.
3. Conclusão
O desenvolvimento de sistemas DSPs tem se popularizado muito, não só pela imensa aplicabilidade que os processadores proporcionam, mas pelas ferramentas de desenvolvimento avançadas que surgiram no mercado, as quais permitem que o desenvolvedor programe o código do dispositivo, depure, otimize e simule o código antes de gerar o programa final. Existem ainda no mercado bibliotecas de domínio público com as principais funções utilizadas em aplicações padrões de DSPs, o que facilita consideravelmente a utilização acadêmica dessa ferramenta.
Muitos DSPs são mais simples que um microprocessador PC o que faz deles mais baratos e, consequentemente, viáveis para o mercado de telecomunicações, multimídia e produtos eletrônicos de consumo.
O mercado de DSP é um leque
aberto para desenvolvedores pois fornece um sem número de aplicações
específicas que alcançam nichos ainda pouco explorados.
Sendo assim, com este trabalho, pudemos adquirir os conhecimentos básicos de um assunto moderno, e que com certeza será de grande valia para futuros projetos desta natureza e principalmente despertará o interesse para o mercado promissor que são os DSPs.
Referências
Bibliográficas
1
Lapsley, P.; BIER, J.; SHOHAM, A.; LEE, E. Buyer's Guide to DSP
Processors,
Fremont.
Berkeley Design Technology, Inc.. Califórnia, 1995.
2
Lapsley, P.; BIER, J.; SHOHAM, A.; LEE, E. DSP Processor Fundamentals:
Architectures
and Features, Fremont. Design Technology, Inc. Califórnia, 1996.
3
Spectron Microsystems - http://www.spectron.com
4
TMS320Cx DSP Solutions,
products suport and News on Texas http://www.dspr.com
5
National - http://www.national.com/appinfo/compactrisc
6
Radar UOL - procura por DSP - http://www.radaruol.com.br