Luiz Carlos da Silveira Jr
Rafael Ottmann
Luis Miguel Yan Chan
Fabio Seiti
Marcus Wrobel
MPEG VÍDEO
Universidade Federal do Paraná
Departamento de Engenharia Elétrica
Professor: Eduardo Parente Ribeiro
Curitiba
09/2000
Índice
2.3.1 Remoção
de informação invisível ao olho humano.
2.3.2 Uso
de tabelas de codificação de tamanho variável
2.3.3 Estimativa/Compensação
de movimento
1 Introdução
O MPEG (Moving Picture Experts Group) é um grupo de pesquisadores da ISO/IEC, que são encarregados de desenvolver padrões internacionais de compressão, descompressão e processamento e codificação de vídeo, áudio e a combinação de ambos. A evolução do MPEG começou:
· MPEG-1, o padrão de armazenamento e leitura de vídeo e áudio em aplicações multimídia. (Novembro de 1992)
· MPEG-2, o padrão da televisão digital (aprovado em Novembro de 1994).
· MPEG-4, o padrão de aplicações multimídia.
o Versão 1, aprovada em outubro de 1998.
o Versão 2, aprovada em dezembro de 1999.
Devido o crescimento dessa tecnologia e as diversidades das aplicações o MPEG-2 tem-se sobressaído sobre os demais padrões, isso se dá em detrimento a sua direta aplicação, a TV, para ser mais preciso a TV a cabo.
2 MPEG-2 Vídeo
A finalidade desse padrão é armazenar de forma organizada a informação de vídeo, de forma a introduzir funcionalidade e flexibilidade aos processos de codificação e decodificação.
2.1 Estrutura Básica de vídeo
Uma seqüência de vídeo contém um numero de imagens ou grupo de imagens, observando que no padrão MPEG-2 a seqüência não corresponde a um filem inteiro, mas somente a poucas imagens.
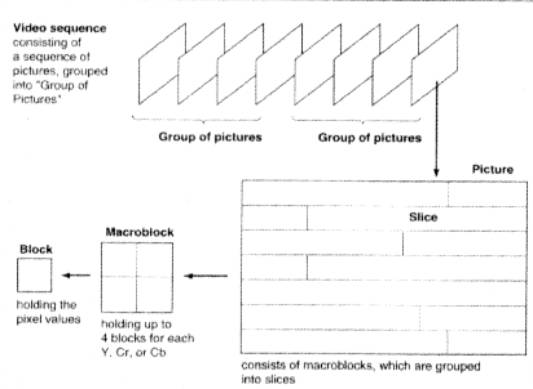
Figura 1
Um grupo de imagens define um conjunto de imagens agrupadas segundo a uma característica determinada.
Os quadros contêm todas as informações de brilho e cor necessárias a uma imagem organizadas em três matrizes: valores de luminância e crominância. O tamanho dessas matrizes depende da resolução e da amostragem.
Imagem corresponde à unidade de informação de vídeo sendo exibida em determinado instante. Ela é divida:
- Tiras – correspondem a uma série de macroblocos e suportam acesso aleatório em uma imagem. São úteis no caso de transmissão com erro, evitando a perda total contida na imagem, caso ocorra o erro somente a tira onde ocorreu o mesmo será perdida, podendo o decodificador continuar na próxima.
- Macrobloco – 4 blocos contendo valores de luminância e um máximo de 8 blocos contendo valores de crominância de um quadro formam o macrobloco.
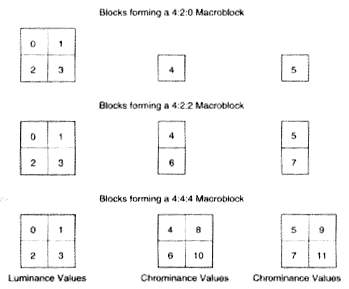
Figura 2
- Blocos – contém um total de 8 linhas e 8 colunas totalizando 64 pixels de luminância e crominância de um quadro.
2.2 Classificação de imagens
As imagens codificadas podem ser classificadas de acordo com sua relação na linha de tempo do vídeo.
- I-Pictures ou intra-coded pictures –
são codificadas de forma que, durante o processo de codificação, não é
necessário qualquer conhecimento sobre as outras imagens que forma a
seqüência de vídeo. Obviamente a 1° imagem de uma seqüência de vídeo é
sempre uma I-Picture, a qual prove informação inicial para as
imagens subseqüentes. Os blocos e macroblocos formando uma I-Picture
são denominados intra-blocks e intra-coded-macrobloks,
respectivamente.
- P-Pictiure ou Predictive Coded Picture
– utiliza-se informação por estimativa de movimento de uma imagem anterior
(imagem de referência), a qual pode ser uma I-Picture ou uma
P-Picture. Uma P-Picture corresponde como algo entre 30% e 50%
do tamanho de uma I-Picture.
- B-Picture ou Bi-Directionally Coded
Picture – utiliza-se informação de imagens prévias bem como de imagens
subseqüentes. Isto é possível porque na codificação o codificador tem
acesso a imagens futuras. As B-Pictures são 50% menores que as P-Pictures.
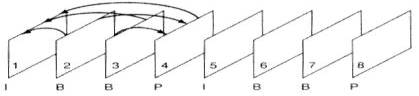
Figura 3
2.3 Compressão MPEG-2
A compressão de dados, segundo definida na norma MPEG-2 video, é obtida através da combinação de 3 técnicas:
- Remoção da informação da imagem que é invisível ao olho humano.
- Uso de tabelas de codificação de tamanho variável (Variable Lenght Code).
- Estimativa/Compensação de movimento.
2.3.1 Remoção de informação invisível ao olho humano
Explora-se a característica de insensibilidade do olho humano com relação a altas freqüências nas mudanças de cores. Para isso, é utilizado um método baseado na DCT (Discret Cossine Transform), que extrai a redundância espacial (semelhança entre um pixel e sua vizinhança). Os valores reais de cor em cada bloco (8x8 pixels) são substituídos por coeficientes de freqüência os quais descreve as transições de cor no bloco.
2.3.1.1 DCT
O transformado co-seno discreto tornou-se objeto de estudo de muitas aplicações de processamento de imagens, devido aos resultados obtidos com essa transformada serem bastante satisfatórios, unindo boa performance com facilidade de implementação computacional.
Para se visualizar a distribuição de energia ao longo da transformada, e especialmente na realização computacional, utiliza-se à representação matricial para a DCT.
O equacionamento matricial da DCT-2d pode-se derivado aplicando-se a propriedade de seqüência separável aos vetores base, que processarão o sinal bidimensional de entrada em dimensões diferentes, sendo o fluxo de transformações direcionado por um vetor base ao longo das linhas da matriz X e pelo outro ao longo das colunas, especificamente.
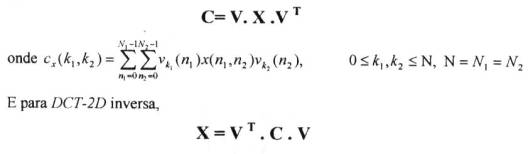
Para imagens em preto e branco a DCT incide sobre os valores de luminância (Gray Values), e em imagens coloridas calcula-se a DCT dos blocos correspondentes aos componentes RGB, ou qualquer outra representação adotada para imagem.

Figura 5
Na figura acima a imagem é em preto e branco com resolução 512x512 pixels, cada pixel da imagem é representado por 8 bits em uma escala de 0 a 255 (preto a branco respectivamente).
Já a figura abaixo visualiza um bloco (8x8 pixels) da imagem acima, os valores na escala de cinza de cada pixel e o efeito da DCT sobre esses pixels.
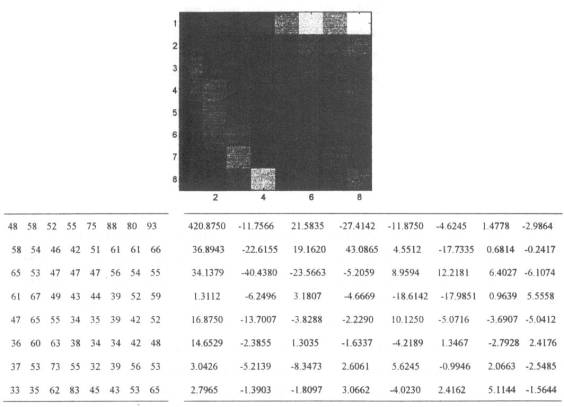
Figura 6
Após a transformação, os coeficientes são quantizados observando-se a energia de cada coeficiente, de modo que sejam quantizados com um maior numero de bits os coeficientes com maiores variâncias e com menor numero de bits os coeficientes os que possuírem menor variância. Devido à propriedade de compactação de energia da DCT, a variância esperada para os coeficientes de uma imagem qualquer é mais ampla para a região de baixa freqüência. Explorando essa característica, utilizam-se 2 técnicas de aproximação para determinar os coeficientes a serem codificados, a codificação por zona e a codificação por limiar (threshold).
Na codificação por zona apenas os coeficientes de uma região especifica do bloco são codificadas. Duas zonas tipicamente usadas na codificação por DCT são apresentadas abaixo.
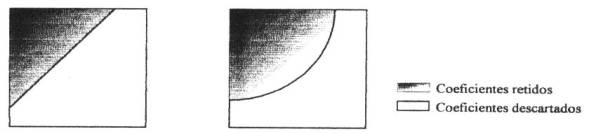
Figura 7
Os coeficientes na região sombreada são codificados enquanto que os da região complementar são descartados, pela atribuição de valor zero.
Na codificação por limiar os coeficientes transformados são comparados com um valor de referencia, e apenas os coeficientes com valores acima dessa referencia são codificados. O passo seguinte à seleção dos coeficientes na subimagem é a alocação da taxa de bits a cada coeficiente remanescente, de acordo com a taxa de bits discriminada previamente para codificação da imagem total. Um procedimento usual para alocação, é a atribuição de uma maior taxa de bits aos coeficientes transformados com maior variância de modo a minimizar o erro médio quadrico, estruturando-se um mapa de alocação de bits com base no qual é feita a quantização dos coeficientes.
Utilizando-se, por exemplo, a quantização escalar (Lloid-Max), cada coeficiente é quantizado individualmente de acordo com o numero de bits alocados para aquela posição no bloco. Esses coeficientes transformados e quantizados são, então, codificados através do mapeamento em um conjunto de palavras-código de tamanho fixos ou variáveis. Pode-se utilizar códigos como Huffman, aritmético, Limpel-Ziv, entre outros, com o intuito de diminuir o numero de bits de representação da imagem para transmissão e armazenamento.
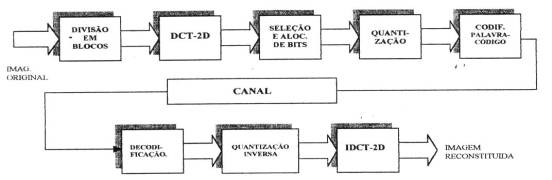
Figura 8
A figura acima apresenta um ambiente de codificação por DCT, que resume as principais etapas do processo. Para obtenção da imagem reconstituída é realizado o processo inverso em cada estagio de codificação. Como o processo não é ideal, distorções são verificadas na imagem reconstituída, as quais em geral são medidas, pela relação sinal-ruído (SRN) e pela relação sinal-ruído de pico (PSNR), entre, imagem original e a imagem reconstituída que podem ser expressos pelas formulas abaixo.

Onde x[i,j] e xr[i,j], representam a imagem original e reconstituída respectivamente.
O ruído de quantização, na imagem reconstituída, se manifesta com a perda localizada de informações de coeficientes transformados, o que afeta como um todo a distribuição de intensidade dos pixels da imagem dentro do bloco.
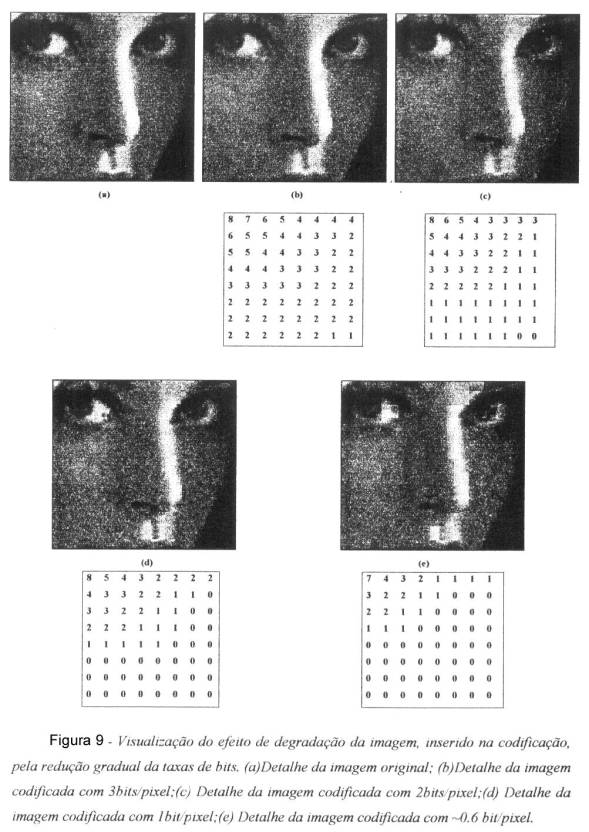
Diversos tipos de degradação resultam do ruído de quantização na codificação de imagem por transformada. Um tipo de degradação é a perda de resolução espacial da imagem. Como dito anteriormente, na alocação de bits tipicamente os coeficientes de alta freqüência são descartados, o que resulta na perda de detalhes da imagem. Pode-se visualizar esse efeito de degradação na figura abaixo, onde são apresentadas imagens reconstituídas com taxas de 3, 2, 1 e 0,6 bit/pixel. Os coeficientes transformados são selecionados e quantizados pelo mapa de alocação de bits anexo a cada imagem. Nota-se que as imagens reconstituídas com taxas menores apresentam menor resolução tornando-se evidentes “borrões”na imagem. Outro tipo de degradação visível e o efeito de blocos, causados pela descontinuidade artificial da intensidade dos pixels nas bordas dos blocos, devido à segmentação e codificação da imagem em blocos de modo independente. Nota-se que o efeito também se acentua com a redução da taxa de bits.
2.3.2 Uso de tabelas de codificação de tamanho variável
Após o processo de quantização, o numero de valor em blocos continua o mesmo, embora haja um grande numero de zeros. Isto é, os 64 valores de pixel em um bloco são substituídos por 64 coeficientes não havendo redução no numero de bits necessárias para representar a informação contida no bloco, Todavia percorrendo-se a matriz de coeficientes resultante do processo, torna-se fácil codificar eficientemente a seqüência de números resultantes utilizando-se técnicas de codificação de tamanho variável.
A norma MPEG-2 define um numero de tabelas com códigos a serem usados para padrões específicos em uma seqüência de dados de coeficientes. A idéia é utilizar códigos curtos para padrões que ocorram muito freqüentemente na seqüência. O código é interpretado como possuindo 2 valores. Um deles chamado run especifica um numero de zeros na frente de um coeficiente não nulo. Outro corresponde ao coeficiente atual recebendo a denominação level. Essa técnica também é conhecida como codificação run-level ou VL (Variable Lenght).
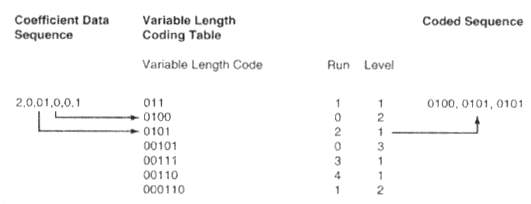
Figura 10
2.3.3 Estimativa/Compensação de movimento
A idéia básica consiste em identificar regiões na imagem que podem ser encontradas em imagens seguintes. Como as imagens ocorrem a uma taxa de 20-30 por segundo, é bastante provável encontrar regiões similares, porem levemente deslocadas em imagens adjacentes.
Para cada macrobloco, o codificador busca um macrobloco igual ou aproximadamente igual na imagem anterior, ou na anterior e posterior, conforme a codificação se dê em P-Pictures o B-Pictures respectivamente. Caso seja encontrado, a diferença entre e o macrobloco original é calcula e codificada em DCT. Em seguida, juntamente com o vetor de movimento (Motion Vector) do macrobloco, a diferença sofre uma modificação rum-level.
Durante o processo de decodificação, utiliza-se o vetor de movimento para encontrar o macrobloco, na imagem anterior (ou futura). Quando encontrado, este macrobloco será combinado com a diferença decodificada de imagem atual para formar o macrobloco correspondente à mesma. No caso ótimo haverá um vetor de movimento valendo zero e uma diferença nula. Neste caso, a codificação do macrobloco não é realizada e quando ocorre a decodificação o macrobloco apresentado permanece na tela.
A compressão utilizando estimação de movimento é inadequado para cenas nas quais bastante objetos movimentam-se rapidamente, pois se torna rara a presença de macroblocos similares movendo-se através da cena. Neste caso, é mais aconselhável a codificação em I-Picture. Igualmente esta técnica não funciona no caos de mudanças de cenas ou cortes.
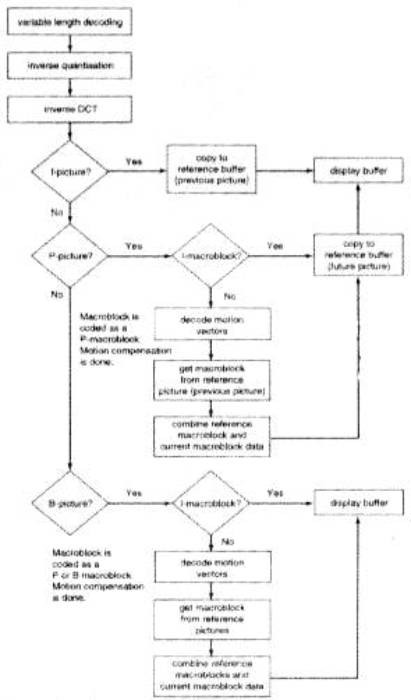
Figura 11
3 Bibliografia
- Internet
http://sweden.mpeg1.de/mpeg1/intro.html
http://icsl.ee.washington.edu/~woobin/papers/General/node2.html
http://www.cselt.it/mpeg/standards/mpeg-2/mpeg-2.htm
- Apostilas
Antonio A. T. P. de Moraes, Tecnologia de Vídeo Digital: dos conceitos básicos à HDTV, Fiberwork Comunicações Ópticas Ltda.
Demétrius da Silva Vital, Codificação de Imagem Utilizando a DCT, UFPA